









S³: Snowflake, Streamlit und semantische Datenverarbeitung
Erfahre, wie man eine semantische KI mithilfe von Streamlit ganz einfach an Snowflake anbinden kann!
Hallo, Freunde! 👋
Wir haben semantha bei großen (Daten-)Kunden integriert. Sie nutzen Snowflake, um hunderte von Datensilos miteinander zu verbinden. Über die API von Snowflake und und den Baukasten von Streamlit können wir für die Nutzer eine sehr effiziente, maßgeschneiderte Benutzeroberfläche anbieten und gleichzeitig auf allen Fähigkeiten von Semantha aufbauen. Das ganze ist schnell umgesetzt: Die Integration besteht aus nur 3 Zeilen Code und für die Gestaltung der Benutzeroberfläche reichen 46 Zeilen!
In diesem Beitrag zeige ich dir:
- Wie du semantische KI-Verarbeitung in deine Apps und Anwendungsfälle integrierst.
- Wie du deiner App mit einem 3-Zeilen-Code „gesunden Menschenverstand“ gibst.
- Wie Du Dich von den Möglichkeiten von Semantha inspirieren lassen kannst!
Hast du deine Ärmel schon hochgekrempelt und willst direkt loslegen? Hier findest du die Beispielanwendung und hier den Code auf GitHub.
So integrierst du semantische KI-Verarbeitung in deine Anwendungen und Anwendungsfälle
Folge einfach diesen Schritten:
Schritt 1. Installiere das entsprechende semantha-Paket für deinen Anwendungsfall mit pip install semantha-streamlit-compare.
Die neueste Version dieser Demo findest du immer direkt auf pypi. Daneben stellen wir natürlich auch ein python-SDK auf pypi zur Verfügung, damit Du alle semantischen Funktionen von semantha nutzen kannst (mehr dazu in zukünftigen Beiträgen, zum Beispiel in unserm Artikel zu Analyse von ESG-Daten).
Hier ist ein Beispiel:
from semantha_streamlit_compare.components.compare import SemanticCompare
compare = SemanticCompare()
compare.build_input(sentences=("First sentence", "Second sentence"))
Schritt 2. Erstelle deine Streamlit-Benutzeroberfläche und rufe den benötigten Semantha-Endpunkt auf.
So sieht eine Beispiel-UI aus, für die man nur 30 Zeilen Code benötigt (den gesamten Code gibt’s auf GitHub):
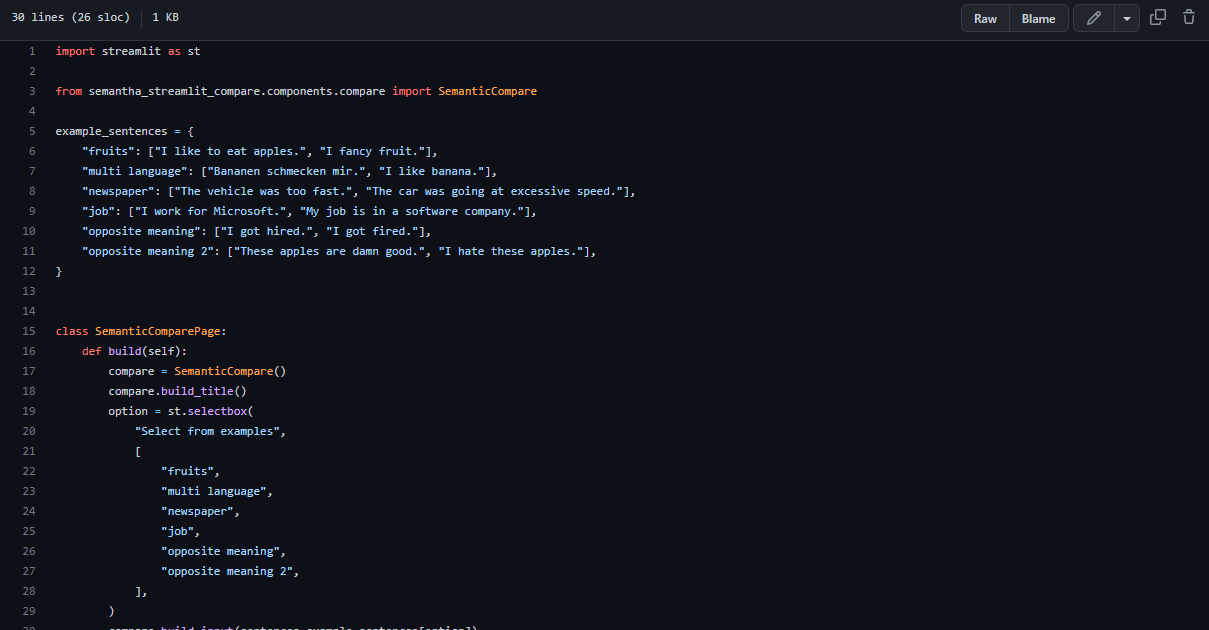
Schritt 3 (optional). Importiere das Paket semantha (Python) in deinen Code und verwende es so, wie du es gerne haben möchtest.
Schritt 4. Fordere einen API-Code an und lass deinen Prototypen laufen.
Um z.B. eine bestimmte Funktion zu verwenden, fordere eine secrets.toml Datei von unserem Support an. Nachdem du die Zugangsdaten bekommen hast, kopiere sie in den Ordner .streamlit/secrets.toml, wie es in der Dokumentation von streamlit beschrieben wird. Möglicherweise musst du die Datei im Stammverzeichnis deiner Streamlit-Anwendung erst noch erstellen – wenn du sie schon hast, kannst du einfach nur den Teil zu Semantha ergänzen.
So sieht unsere secrets.toml-Datei aus:
[semantha]
server_url="URL_TO_SERVER"
api_key="YOUR_API_KEY_ISSUED"
domain="USAGE_DOMAIN_PROVIDED_TO_YOU"
documenttype="document_with_contradiction_enabled"
Wie du deiner App mit einem 3-Zeiler „gesunden Menschenverstand“ gibst
Wenn du die obigen Schritte durchgeführt hast, hast du „gesunden Menschenverstand“ in deine App eingebaut. Sie versteht nun automatisch, wenn Dinge ähnlich, unterschiedlich oder von gegensätzlicher Bedeutung sind. Erweitere diese Idee auf Dokumente und all die unstrukturierten Informationen, mit denen du jeden Tag arbeitest. Du weißt, wohin das führen könnte… zu einem verlässlichen Begleiter bei deiner täglichen Wissensarbeit!
Lass dich inspirieren!
Schau dir dieses Video an, um zu sehen, was andere auf der Grundlage von Streamlit entwickelt haben:

Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
Joe zeigt, wie man semantha® nutzen kann, um die Regelungen aus den ESRS mit den bekannten GRI Standards zu vergleichen – die Anwendung ist auch auf Streamlit entwickelt 😉.
Du kennst deine Anwendungsfälle am besten – und du weißt, wo ein:e Kollege:in (in diesem Fall nicht ein Mensch, sondern eine KI) sehr hilfreich sein könnte!
Fortsetzung folgt
Wir werden in den kommenden Beiträgen weitere Anwendungsfälle vorstellen, darunter:
- Wie du sprachübergreifend Filmzitaten suchen kannst.
- ESG-insights: Wie du unstrukturierte Daten aus Snowflake mit Semantha analysieren kannst.
- Wie du Ausschreibungen/RFPs mit semantha auswerden kannst.
Wenn du Fragen hast, schreibe mir auf LinkedIn, Twitter, oder melde dich per E-Mail. Oder buche dir einen persönlichen deep dive (gerne mit deinen Daten).
Happy coding! 💻
Dieser Post ist erstmals auf dem Streamlit blog als Using Streamlit for semantic processing with semantha erschienen.
Veröffentlicht am 02. Febraur 2023.