









Bulk Claim Analysis & Comparison
In your company, many procedures on the same topic are processed. Despite always having similar presentations in the pleas and repetitive correspondence with companies, insurers and clients, these documents have to be read and analysed at great expense. Although content can be divided into certain categories, the problem is that similar issues are formulated in completely different ways, which makes it seem impossible to automate the processes.
You have to reply to numerous pleas, such as lawsuits or statements of defence, and repeatedly come across similar submissions. In most cases, you can use excerpts from past responses as a basis for the new plea. However, the classification of the individual submissions of the newly received pleas is the biggest challenge.
-
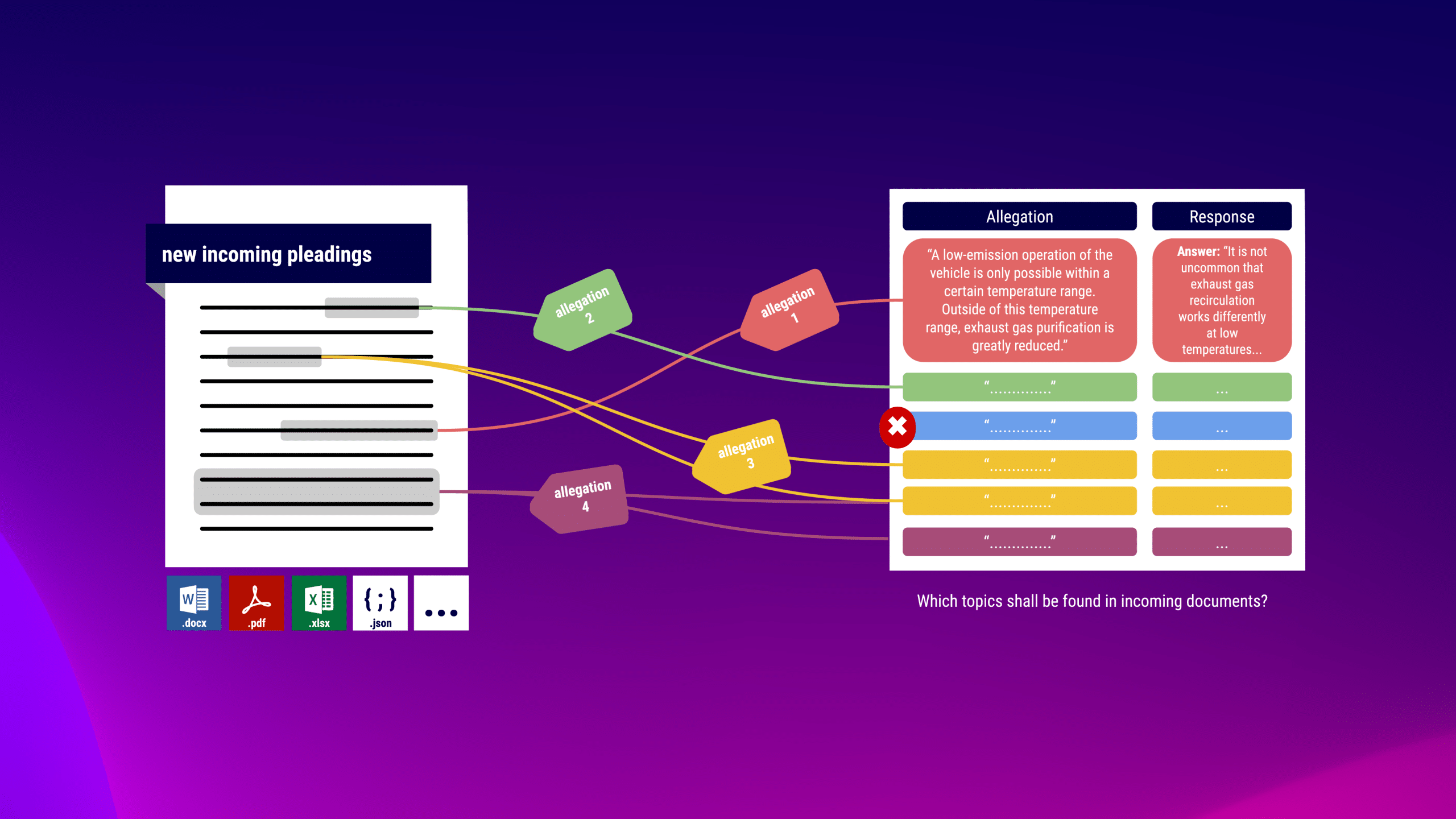
In our library, you can define content for which new incoming contracts should be checked. semantha® finds the passages based on the meaning, independent of the word choice and completely without “training” with your data. This way, the appropriate response is quickly found for every submission.
-

Using our Compare, you can compare previous correspondence with new incoming correspondence. semantha® shows you which contents match and which contents are missing – out of the box and without time-consuming training with your data.
-

With our data extraction, you can easily extract relevant data points from documents and process them further. The combination with semantha’s® natural language understanding is particularly helpful, as it allows you to find and extract data points in specific contexts.