









Law Firms
Bulk Claim Analysis & Comparison
In your company, many procedures on the same topic are processed. Despite always having similar presentations in the pleas and repetitive correspondence with companies, insurers and clients, these documents have to be read and analysed at great expense. Although content can be divided into certain categories, the problem is that similar issues are formulated in completely different ways, which makes it seem impossible to automate the processes.
You have to reply to numerous pleas, such as lawsuits or statements of defence, and repeatedly come across similar submissions. In most cases, you can use excerpts from past responses as a basis for the new plea. However, the classification of the individual submissions of the newly received pleas is the biggest challenge.
-
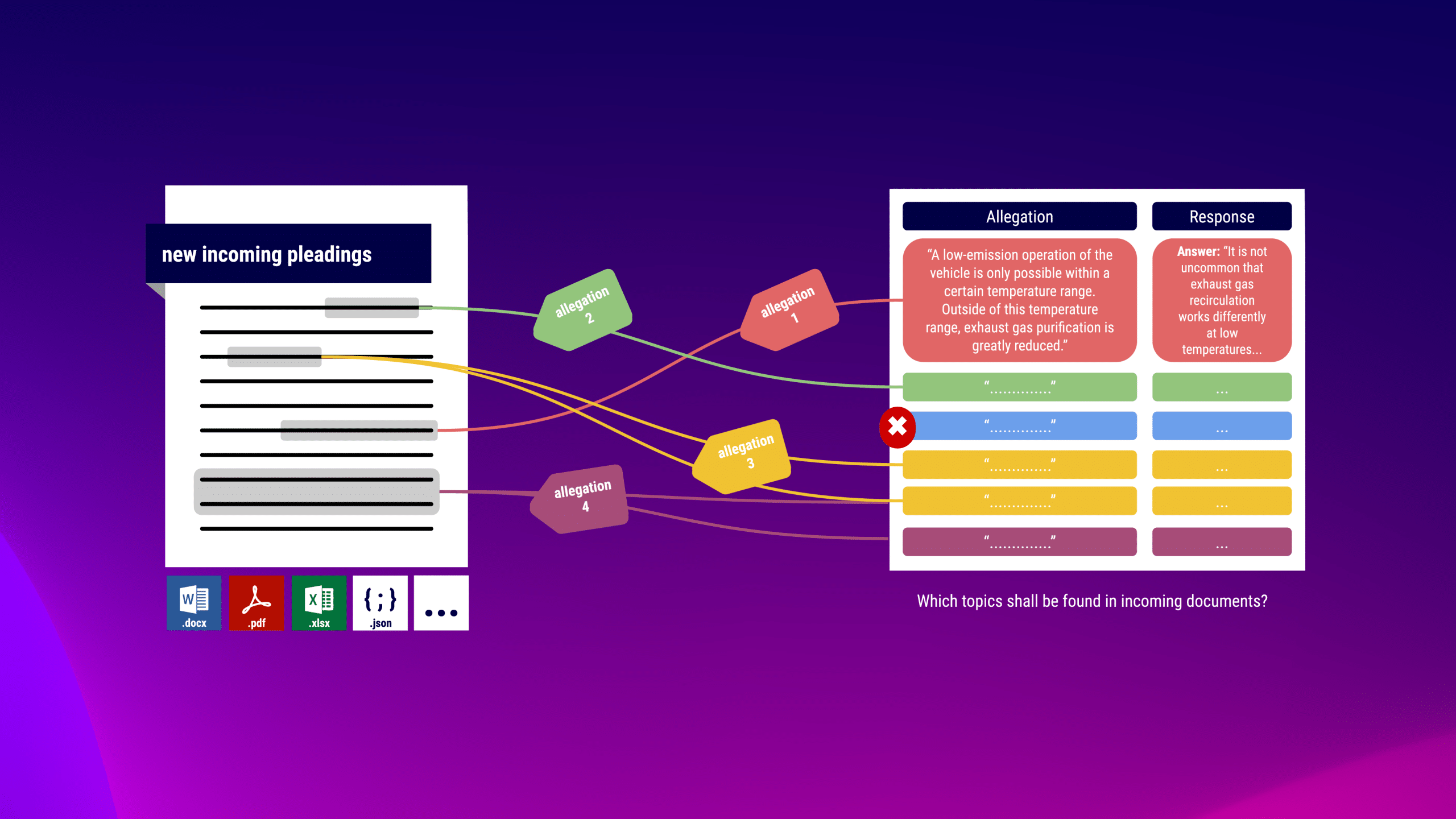
In our library, you can define content for which new incoming contracts should be checked. semantha® finds the passages based on the meaning, independent of the word choice and completely without “training” with your data. This way, the appropriate response is quickly found for every submission.
-

Using our Compare, you can compare previous correspondence with new incoming correspondence. semantha® shows you which contents match and which contents are missing – out of the box and without time-consuming training with your data.
-

With our data extraction, you can easily extract relevant data points from documents and process them further. The combination with semantha’s® natural language understanding is particularly helpful, as it allows you to find and extract data points in specific contexts.
Correspondence Automation
In your company masses of correspondences have to be processed and allocated every day. Each mail must be analysed at great expense before the next step can be taken. It is quite possible to assign certain categories, but the problem is that similar facts are formulated very differently, which apparently makes it impossible to automate this process.
-
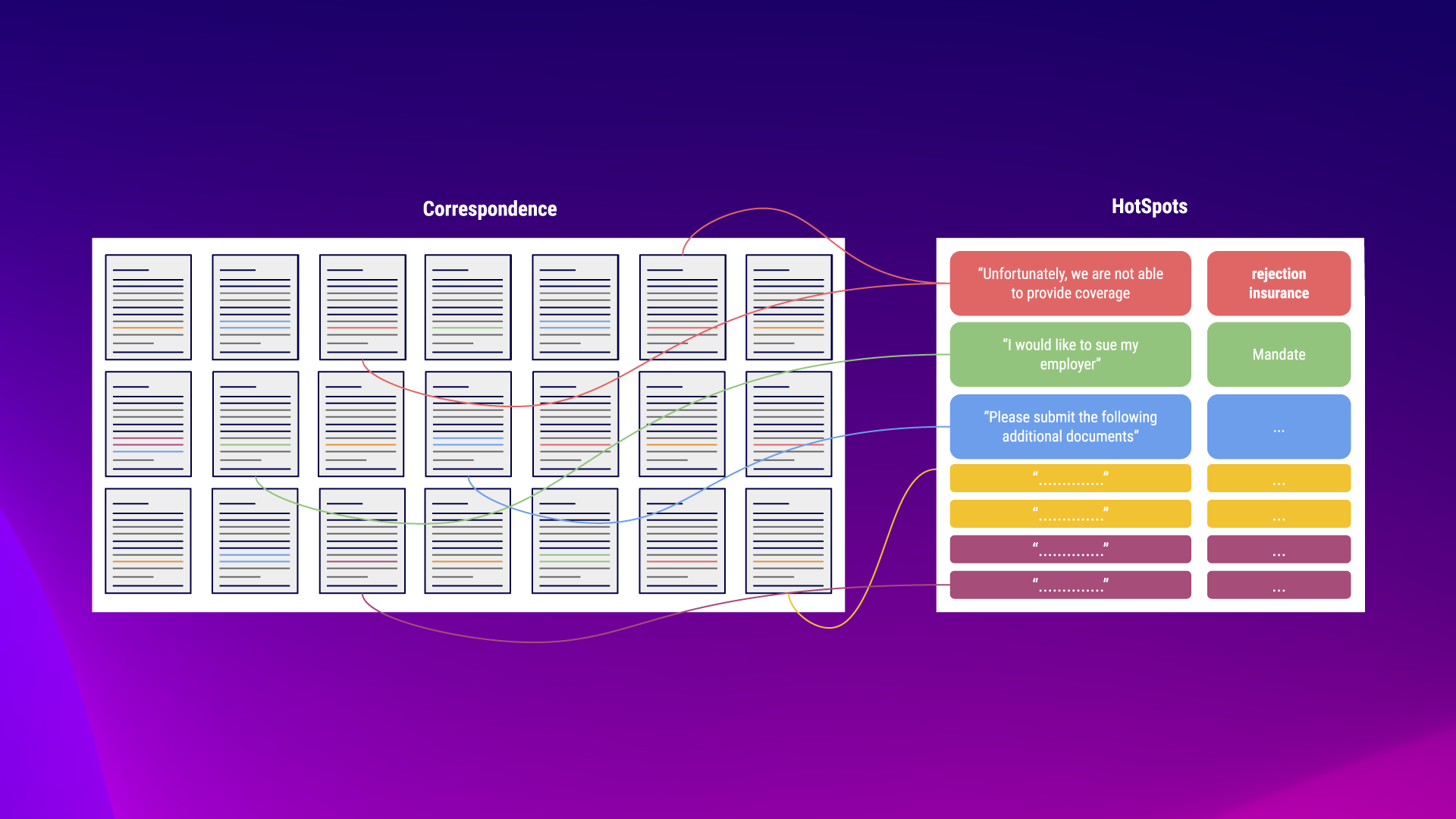
With semantha® you can automatically classify and assign incoming letters, no matter how they are formulated, regardless of the choice of words.
-

With our data extraction, you can easily extract relevant data points from Correspondences and process them further. The combination with semantha’s® natural language understanding is particularly helpful, as it allows you to find and extract data points in specific contexts.
Document Analysis & Comparison
In your company, documents have to be reviewed regularly and with a high manual effort. In most cases, the content to be reviewed is similar. The problem is that every document is worded and structured differently, which makes automation impossible.
-
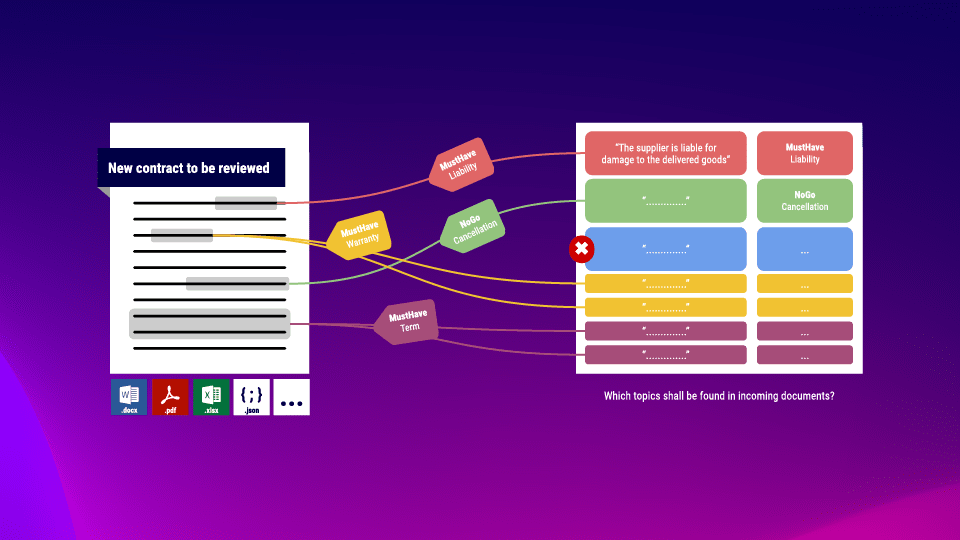
In our library, you can define content for which new incoming documents are to be analysed against. semantha® finds the passages based on their meaning, regardless of the choice of words and without any “training” with your data. Thus, relevant contents of a document are found quickly and efficiently.
-

Using our Compare, you can compare already reviewed documents with new incoming documents. semantha® shows you which content matches and which content is missing – out of the box and without time-consuming training with your data.
-

In addition, you can use our Compare feature to compare different versions of a document. semantha® shows you which contents have remained the same and which areas have been changed or removed completely.
-
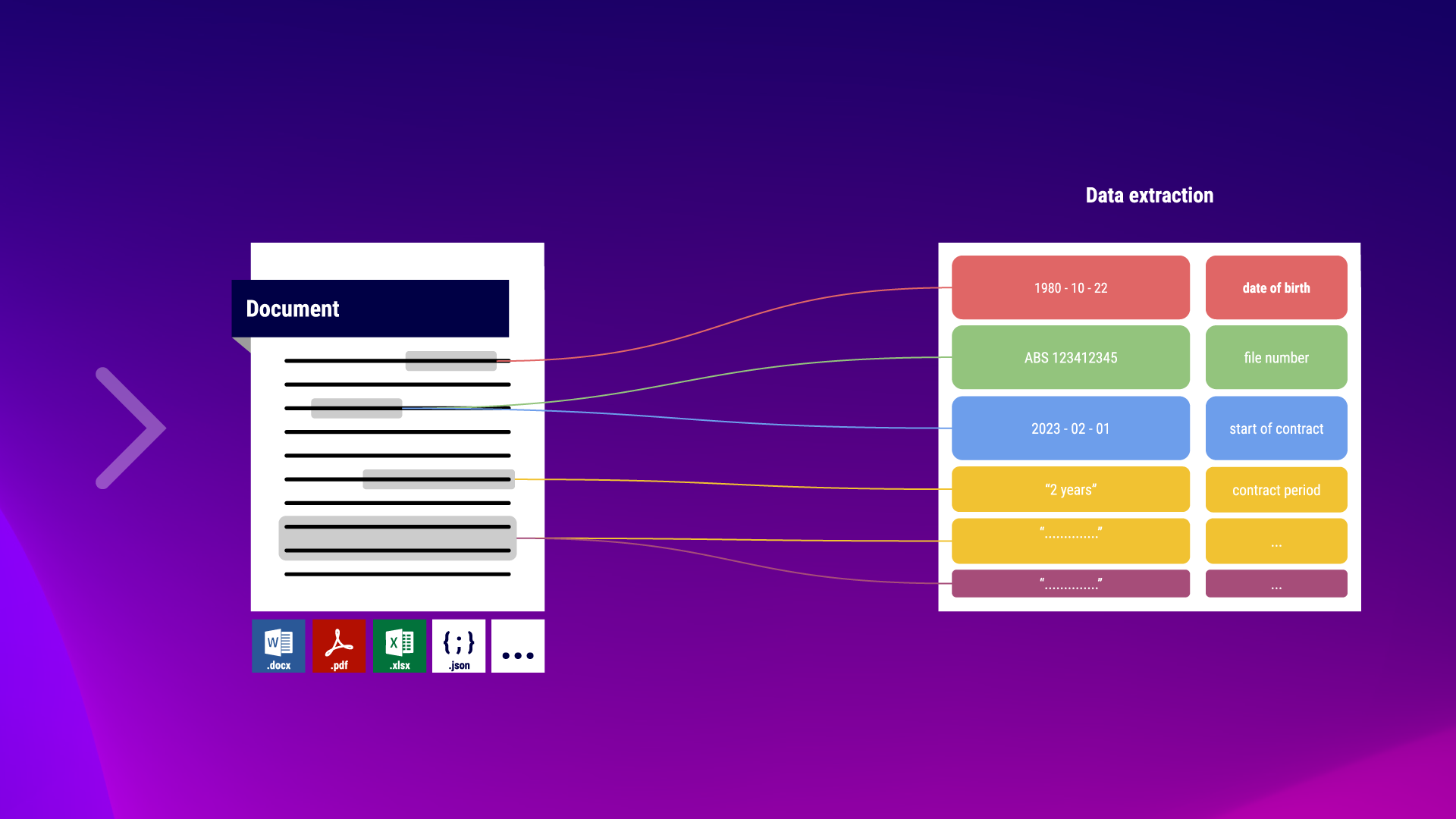
With our data extraction, you can easily extract relevant data points from documents and process them further. The combination with semantha’s® natural language understanding is particularly helpful, as it allows you to find and extract data points in specific contexts.
These use cases might also interest you…
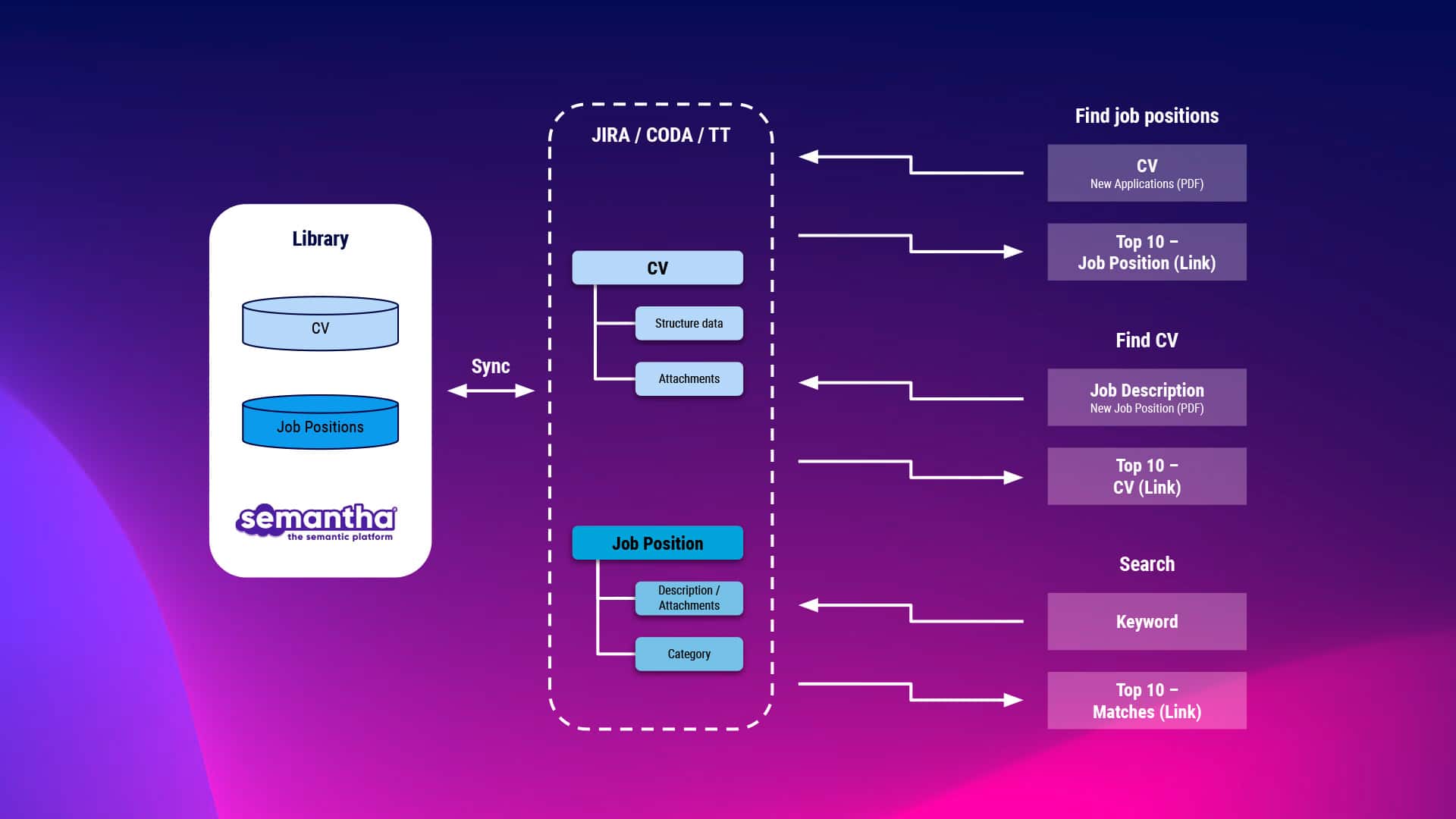
CV Matching
With semantha we have developed an AI tool that overcomes the weaknesses of conventional matching tools. The application does not compare whether certain terms occur in documents, but reads the documents at the level of meaning. And it does so within a few moments.
- Ranking of top candidates at the touch of a button
- Overview of the best internal candidates for any skills
- More objective selection of candidates
- Acceleration of the selection process by up to 50%
- More time for interviews to ensure human fit

Knowledge Management
Your company has large masses of unstructured text documents. One of the daily challenges is to search these documents for specific content, whereby normal search functions only offer a simple “keyword search” that does not lead to the desired results. This is particularly due to the fact that, on the one hand, it is not known exactly how a topic was formulated and, on the other hand, the same topics are also formulated quite differently in the various documents.