









Document Analysis & Comparison
In your company, documents have to be reviewed regularly and with a high manual effort. In most cases, the content to be reviewed is similar. The problem is that every document is worded and structured differently, which makes automation impossible.
-
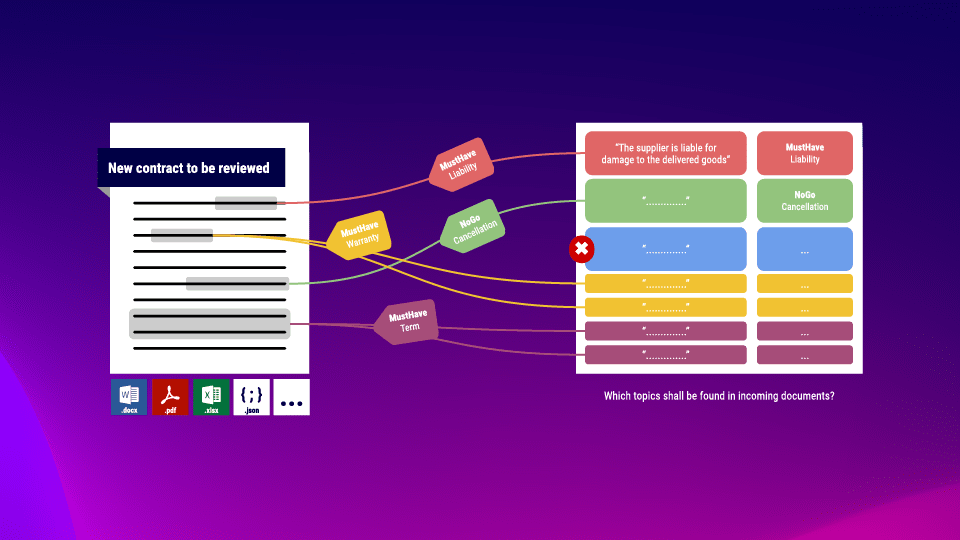
In our library, you can define content for which new incoming documents are to be analysed against. semantha® finds the passages based on their meaning, regardless of the choice of words and without any “training” with your data. Thus, relevant contents of a document are found quickly and efficiently.
-

Using our Compare, you can compare already reviewed documents with new incoming documents. semantha® shows you which content matches and which content is missing – out of the box and without time-consuming training with your data.
-

In addition, you can use our Compare feature to compare different versions of a document. semantha® shows you which contents have remained the same and which areas have been changed or removed completely.
-
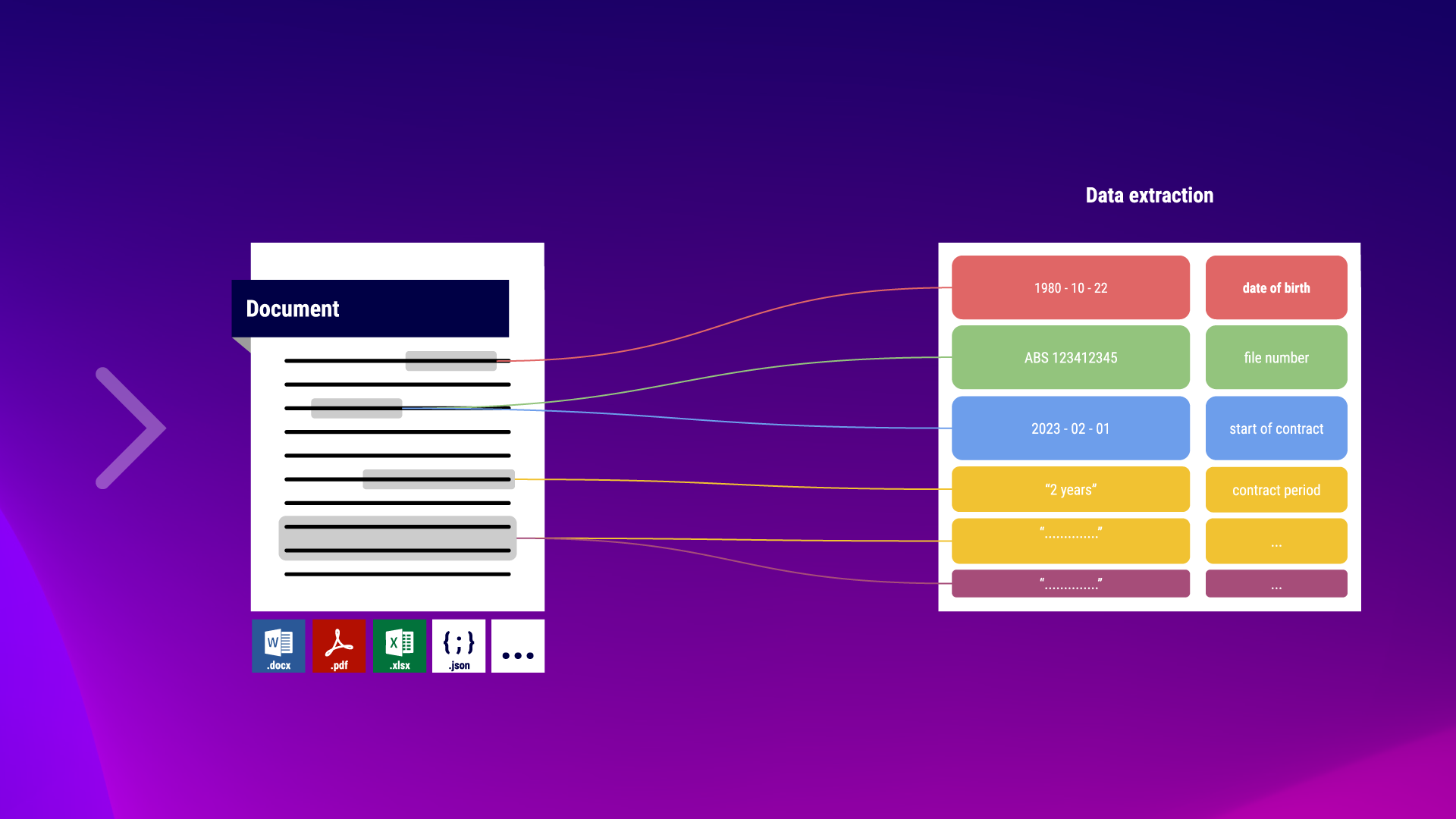
With our data extraction, you can easily extract relevant data points from documents and process them further. The combination with semantha’s® natural language understanding is particularly helpful, as it allows you to find and extract data points in specific contexts.